در
قسمتهای قبل، نحوهی تعریف جزیرههای تعاملی Blazor Server را به همراه نکات مرتبط با آنها بررسی کردیم. برای مثال مشاهده کردیم که چون Blazor Server و SSR هر دو بر روی سرور اجرا میشوند، از لحاظ دسترسی به اطلاعات و کار با سرویسها، هماهنگی کاملی دارند و میتوان کدهای یکسان و یکدستی را در اینجا بکار گرفت. در Blazor 8x، امکان تعریف جزیرههای تعاملی Blazor WASM نیز وجود دارد که به همراه تعدادی نکتهی ویژه، در مورد نحوهی مدیریت سرویسهای مورد استفادهی در این کامپوننتها است.
معرفی برنامهی Blazor WASM این مطلب
در این مطلب قصد داریم دقیقا قسمت جزیرهی تعاملی Blazor Server همان برنامهی مطلب قبل را توسط یک جزیرهی تعاملی Blazor WASM بازنویسی کنیم و با نکات و تفاوتهای ویژهی آن آشنا شویم. یعنی زمانیکه صفحهی SSR نمایش جزئیات یک محصول ظاهر میشود، نحوهی رندر و پردازش کامپوننت نمایش محصولات مرتبط و مشابه، اینبار یک جزیرهی تعاملی Blazor WASM باشد. بنابراین قسمت عمدهای از کدهای این دو قسمت یکی است؛ فقط نحوهی دسترسی به سرویسها و محل قرارگیری تعدادی از فایلها، متفاوت خواهد بود.
ایجاد یک پروژهی جدید Blazor WASM تعاملی در دات نت 8
بنابراین در ادامه، در ابتدای کار نیاز است یک پوشهی جدید را برای این پروژه، ایجاد کرده و بجای انتخاب interactivity از نوع Server:
dotnet new blazor --interactivity Server
اینبار برای اجرای در مرورگر توسط فناوری وباسمبلی، نوع WebAssembly را انتخاب کنیم:
dotnet new blazor --interactivity WebAssembly
در این حالت، Solution ای که ایجاد میشود، به همراه دو پروژهاست (برخلاف پروژههای Blazor Server تعاملی که فقط شامل یک پروژهی سمت سرور هستند):
الف) یک پروژهی سمت سرور (برای تامین backend و API و سرویسهای مرتبط)
ب) یک پروژهی سمت کلاینت (برای اجرای مستقیم درون مرورگر کاربر؛ بدون داشتن وابستگی مستقیمی به اجزای برنامهی سمت سرور)
این ساختار، خیلی شبیه به ساختار پروژههای نگارش قبلی Blazor از نوع Hosted Blazor WASM است که در آن، یک پروژهی ASP.NET Core هاست کنندهی پروژهی Blazor WASM وجود دارد و یکی از کارهای اصلی آن، فراهم ساختن Web API مورد استفادهی در پروژهی WASM است.
در حالتیکه نوع تعاملی بودن پروژه را Server انتخاب کنیم (مانند مثال
قسمت پنجم)، فایل Program.cs آن به همراه دو تعریف مهم زیر است که امکان تعریف کامپوننتهای تعاملی سمت سرور را میسر میکنند:
// ...
builder.Services.AddRazorComponents()
.AddInteractiveServerComponents();
// ...
app.MapRazorComponents<App>()
.AddInteractiveServerRenderMode();
مهمترین قسمتهای آن، متدهای AddInteractiveServerComponents و AddInteractiveServerRenderMode هستند که server-side rendering را به همراه امکان داشتن کامپوننتهای تعاملی، ممکن میکنند.
این تعاریف در فایل Program.cs (پروژهی سمت سرور) قالب جدید Blazor WASM به صورت زیر تغییر میکنند تا امکان تعریف کامپوننتهای تعاملی سمت کلاینت از نوع وباسمبلی، میسر شود:
// ...
builder.Services.AddRazorComponents()
.AddInteractiveWebAssemblyComponents();
// ...
app.MapRazorComponents<App>()
.AddInteractiveWebAssemblyRenderMode()
.AddAdditionalAssemblies(typeof(Counter).Assembly); نیاز به تغییر معماری برنامه جهت کار با جزایر Blazor WASM
همانطور که در
قسمت پنجم مشاهده کردیم، تبدیل کردن یک کامپوننت Blazor، به کامپوننتی تعاملی برای اجرای در سمت سرور، بسیار سادهاست؛ فقط کافی است rendermode@ آنرا به InteractiveServer تغییر دهیم تا ... کار کند. اما تبدیل همان کامپوننت نمایش محصولات مرتبط، به یک جزیرهی وباسمبلی، نیاز به تغییرات قابل ملاحظهای را دارد؛ از این لحاظ که اینبار این قسمت قرار است بر روی مرورگر کاربر اجرا شود و نه بر روی سرور. در این حالت دیگر کامپوننت ما دسترسی مستقیمی را به سرویسهای سمت سرور ندارد و برای رسیدن به این مقصود باید از یک Web API در سمت سرور کمک بگیرد و برای کار کردن با آن API در سمت کلاینت، از سرویس HttpClient استفاده کند. به همین جهت، پیاده سازی معماری این روش، نیاز به کار بیشتری را دارد:

همانطور که ملاحظه میکنید، برای فعالسازی یک جزیرهی تعاملی وباسمبلی، نمیتوان کامپوننت RelatedProducts آنرا مستقیما در پروژهی سمت سرور قرار داد و باید آنرا به پروژهی سمت کلاینت منتقل کرد. در ادامه پیاده سازی کامل این پروژه را با توجه به این تغییرات بررسی میکنیم.
مدل برنامه: رکوردی برای ذخیره سازی اطلاعات یک محصول
از این جهت که مدل برنامه (که در
قسمت پنجم معرفی شد) در دو پروژهی Client و سرور قابل استفادهاست، به همین جهت مرسوم است یک پروژهی سوم Shared را نیز به جمع دو پروژهی جاری solution اضافه کرد و فایل این مدل را در آن قرار داد. بنابراین این فایل را از پوشهی Models پروژهی سرور به پوشهی Models پروژهی جدید BlazorDemoApp.Shared در مسیر جدید BlazorDemoApp.Shared\Models\Product.cs منتقل میکنیم. مابقی کدهای آن با
قسمت پنجم تفاوتی ندارد.
سپس به فایل csproj. پروژهی کلاینت مراجعه کرده و ارجاعی را به پروژهی جدید BlazorDemoApp.Shared اضافه میکنیم:
<Project Sdk="Microsoft.NET.Sdk.BlazorWebAssembly">
<PropertyGroup>
<TargetFramework>net8.0</TargetFramework>
</PropertyGroup>
<ItemGroup>
<ProjectReference Include="..\BlazorDemoApp.Shared\BlazorDemoApp.Shared.csproj" />
</ItemGroup>
</Project>
نیازی نیست تا اینکار را برای پروژهی سرور نیز تکرار کنیم؛ از این جهت که ارجاعی به پروژهی کلاینت، در پروژهی سرور وجود دارد که سبب دسترسی به این پروژهی Shared هم میشود.
سرویس برنامه: سرویسی برای بازگشت لیست محصولات
چون Blazor Server و صفحات SSR آن هر دو بر روی سرور اجرا میشوند، از لحاظ دسترسی به اطلاعات و کار با سرویسها، هماهنگی کاملی وجود داشته و میتوان کدهای یکسان و یکدستی را در اینجا بکار گرفت. یعنی هنوز هم همان مسیر قبلی سرویس Services\ProductStore.cs در این پروژهی سمت سرور نیز برقرار است و نیازی به تغییر مسیر آن نیست. البته بدیهی است چون این پروژه جدید است، باید این سرویس را در فایل Program.cs برنامهی سمت سرور به صورت زیر معرفی کرد تا در فایل razor برنامهی آن قابل دسترسی شود:
builder.Services.AddScoped<IProductStore, ProductStore>();
تکمیل فایل Imports.razor_ پروژهی سمت سرور
جهت سهولت کار با برنامه، یک سری مسیر و using را نیاز است به فایل Imports.razor_ پروژهی سمت سرور اضافه کرد:
@using static Microsoft.AspNetCore.Components.Web.RenderMode
// ...
@using BlazorDemoApp.Client.Components.Store
@using BlazorDemoApp.Client.Components
سطر اول سبب میشود تا بتوان به سادگی به اعضای کلاس استاتیک RenderMode، در برنامهی سمت سرور دسترسی یافت. دو using جدید دیگر سبب سهولت دسترسی به کامپوننتهای قرارگرفتهی در این مسیرها در صفحات SSR برنامهی سمت سرور میشوند.
تکمیل صفحهی نمایش لیست محصولات
کدها و مسیر کامپوننت ProductsList.razor، با
قسمت پنجم دقیقا یکی است. این صفحه، یک صفحهی SSR بوده و در همان سمت سرور اجرا میشود و دسترسی آن به سرویسهای سمت سرور نیز ساده بوده و همانند قبل است.
تکمیل صفحهی نمایش جزئیات یک محصول
کدها و مسیر کامپوننت ProductDetails.razor، با
قسمت پنجم دقیقا یکی است. این صفحه، یک صفحهی SSR بوده و در همان سمت سرور اجرا میشود و دسترسی آن به سرویسهای سمت سرور نیز ساده بوده و همانند قبل است ... البته بجز یک تغییر کوچک:
<RelatedProducts ProductId="ProductId" @rendermode="@InteractiveWebAssembly"/>
در اینجا حالت رندر این کامپوننت، به InteractiveWebAssembly تغییر میکند. یعنی اینبار قرار است تبدیل به یک جزیرهی وباسمبلی شود و نه یک جزیرهی Blazor Server که آنرا در
قسمت پنجم بررسی کردیم.
تکمیل کامپوننت نمایش لیست محصولات مشابه و مرتبط
پس از این توضیحات، به اصل موضوع این قسمت رسیدیم! کامپوننت سمت سرور RelatedProducts.razor
قسمت پنجم ، از آنجا cut شده و به مسیر جدید BlazorDemoApp.
Client\Components\Store\RelatedProducts.razor منتقل میشود. یعنی کاملا به پروژهی وباسمبلی منتقل میشود. بنابراین کدهای آن دیگر دسترسی مستقیمی به سرویس دریافت اطلاعات محصولات ندارند و برای اینکار نیاز است در سمت سرور، یک Web API Controller را تدارک ببینیم:
using BlazorDemoApp.Services;
using Microsoft.AspNetCore.Mvc;
namespace BlazorDemoApp.Controllers;
[ApiController]
[Route("/api/[controller]")]
public class ProductsController : ControllerBase
{
private readonly IProductStore _store;
public ProductsController(IProductStore store) => _store = store;
[HttpGet("[action]")]
public IActionResult Related([FromQuery] int productId) => Ok(_store.GetRelatedProducts(productId));
}
این کلاس در مسیر Controllers\ProductsController.cs پروژهی سمت سرور قرار میگیرد و کار آن، بازگشت اطلاعات محصولات مشابه یک محصول مشخص است.
برای اینکه مسیریابی این کنترلر کار کند، باید به فایل Program.cs برنامه، مراجعه و سطرهای زیر را اضافه کرد:
builder.Services.AddControllers();
// ...
app.MapControllers();
یک نکته: همانطور که مشاهده میکنید، در Blazor 8x، امکان استفاده از دو نوع مسیریابی یکپارچه، در یک پروژه وجود دارد؛ یعنی Blazor routing و ASP.NET Core endpoint routing. بنابراین در این پروژهی سمت سرور، هم میتوان صفحات SSR و یا Blazor Server ای داشت که مسیریابی آنها با page@ مشخص میشوند و همزمان کنترلرهای Web API ای را داشت که بر اساس سیستم مسیریابی ASP.NET Core کار میکنند.
بر این اساس در پروژهی سمت کلاینت، کامپوننت RelatedProducts.razor باید با استفاده از سرویس HttpClient، اطلاعات درخواستی را از Web API فوق دریافت و همانند قبل نمایش دهد که تغییرات آن به صورت زیر است:
@using BlazorDemoApp.Shared.Models
@inject HttpClient Http
<button class="btn btn-outline-secondary" @onclick="LoadRelatedProducts">Related products</button>
@if (_loadRelatedProducts)
{
@if (_relatedProducts == null)
{
<p>Loading...</p>
}
else
{
<div class="mt-3">
@foreach (var item in _relatedProducts)
{
<a href="/ProductDetails/@item.Id">
<div class="col-sm">
<h5 class="mt-0">@item.Title (@item.Price.ToString("C"))</h5>
</div>
</a>
}
</div>
}
}
@code{
private IList<Product>? _relatedProducts;
private bool _loadRelatedProducts;
[Parameter]
public int ProductId { get; set; }
private async Task LoadRelatedProducts()
{
_loadRelatedProducts = true;
var uri = $"/api/products/related?productId={ProductId}";
_relatedProducts = await Http.GetFromJsonAsync<IList<Product>>(uri);
}
}
و ... همین! اکنون برنامه قابل اجرا است و به محض نمایش صفحهی جزئیات یک محصول انتخابی، کامپوننت RelatedProducts، در حالت وباسمبلی جزیرهای اجرا شده و لیست این محصولات مرتبط را نمایش میدهد.
در ادامه یکبار برنامه را اجرا میکنیم و ... بلافاصله پس از انتخاب صفحهی نمایش جزئیات یک محصول، با خطای زیر مواجه خواهیم شد!
System.InvalidOperationException: Cannot provide a value for property 'Http' on type 'RelatedProducts'.
There is no registered service of type 'System.Net.Http.HttpClient'.
اهمیت درنظر داشتن pre-rendering در حالت جزیرههای وباسمبلی
استثنائی را که مشاهده میکنید، به علت pre-rendering سمت سرور این کامپوننت، رخدادهاست.
زمانیکه کامپوننتی را به این نحو رندر میکنیم:
<RelatedProducts ProductId="ProductId" @rendermode="@InteractiveWebAssembly"/>
به صورت پیشفرض در آن pre-rendering نیز فعال است؛ یعنی این کامپوننت دوبار رندر میشود:
الف) یکبار در سمت سرور تا HTML حداقل قالب آن، به همراه سایر قسمتهای صفحهی SSR جاری به سمت مرورگر کاربر ارسال شود.
ب) یکبار هم در سمت کلاینت، زمانیکه Blazor WASM بارگذاری شده و فعال میشود.
استثنائی را که مشاهده میکنیم، مربوط به حالت الف است. یعنی زمانیکه برنامهی ASP.NET Core هاست برنامه، سعی میکند کامپوننت RelatedProducts را در سمت سرور رندر کند، اما ... ما سرویس HttpClient را در آن ثبت و فعالسازی نکردهایم. به همین جهت است که عنوان میکند این سرویس را پیدا نکردهاست. برای رفع این مشکل، چندین راهحل وجود دارند که در ادامه آنها را بررسی میکنیم.
راهحل اول: ثبت سرویس HttpClient در سمت سرور
یک راهحل مواجه شدن با مشکل فوق، ثبت سرویس HttpClient در فایل Program.cs برنامهی سمت سرور به صورت زیر است:
builder.Services.AddScoped(sp => new HttpClient
{
BaseAddress = new Uri("http://localhost/")
});
پس از این تعریف، کامپوننت RelatedProducts، در حالت prerendering ابتدایی سمت سرور هم کار میکند و برنامه با استثنائی مواجه نخواهد شد.
راهحل دوم: استفاده از polymorphism یا چندریختی
برای اینکار اینترفیسی را طراحی میکنیم که قرارداد نحوهی تامین اطلاعات مورد نیاز کامپوننت RelatedProducts را ارائه میکند. سپس یک پیاده سازی سمت سرور را از آن خواهیم داشت که مستقیما به بانک اطلاعاتی رجوع میکند و همچنین یک پیاده سازی سمت کلاینت را که از HttpClient جهت کار با Web API استفاده خواهد کرد.
از آنجائیکه این قرارداد نیاز است توسط هر دو پروژهی سمت سرور و سمت کلاینت استفاده شود، باید آنرا در پروژهی Shared قرار داد تا بتوان ارجاعاتی از آنرا به هر دو پروژه اضافه کرد؛ برای مثال در فایل BlazorDemoApp.Shared\Data\IProductStore.cs به صورت زیر:
using BlazorDemoApp.Shared.Models;
namespace BlazorDemoApp.Shared.Data;
public interface IProductStore
{
IList<Product> GetAllProducts();
Product GetProduct(int id);
Task<IList<Product>?> GetRelatedProducts(int productId);
}
این همان اینترفیسی است که پیشتر در فایل ProductStore.cs سمت سرور تعریف کرده بودیم؛ با یک تفاوت: متد GetRelatedProducts آن async تعریف شدهاست که نمونهی سمت کلاینت آن باید با متد GetFromJsonAsync کار کند که async است.
پیاده سازی سمت سرور این اینترفیس، کاملا مهیا است و فقط نیاز به تغییر زیر را دارد تا با خروجی Task دار هماهنگ شود:
public Task<IList<Product>?> GetRelatedProducts(int productId)
{
var product = ProductsDataSource.Single(x => x.Id == productId);
return Task.FromResult<IList<Product>?>(ProductsDataSource.Where(p => product.Related.Contains(p.Id))
.ToList());
}
و اکشن متد متناظر هم باید به صورت زیر await دار شود تا خروجی صحیحی را ارائه دهد:
[HttpGet("[action]")]
public async Task<IActionResult> Related([FromQuery] int productId) =>
Ok(await _store.GetRelatedProducts(productId));
همچنین پیشتر سرویس آن در فایل Program.cs برنامهی سمت سرور، ثبت شدهاست و نیاز به نکتهی خاصی ندارد.
در ادامه نیاز است یک پیاده سازی سمت کلاینت را نیز از آن تهیه کنیم که در فایل BlazorDemoApp.Client\Data\ClientProductStore.cs درج خواهد شد:
public class ClientProductStore : IProductStore
{
private readonly HttpClient _httpClient;
public ClientProductStore(HttpClient httpClient) => _httpClient = httpClient;
public IList<Product> GetAllProducts() => throw new NotImplementedException();
public Product GetProduct(int id) => throw new NotImplementedException();
public Task<IList<Product>?> GetRelatedProducts(int productId) =>
_httpClient.GetFromJsonAsync<IList<Product>>($"/api/products/related?productId={productId}");
}
در این بین بر اساس نیاز کامپوننت نمایش لیست محصولات مشابه، فقط به متد GetRelatedProducts نیاز داریم؛ بنابراین فقط همین مورد در اینجا پیاده سازی شدهاست. پس از این تعریف، نیاز است سرویس فوق را در فایل Program.cs برنامهی کلاینت هم ثبت کرد (به همراه سرویس HttpClient ای که در سازندهی آن تزریق میشود):
builder.Services.AddScoped<IProductStore, ClientProductStore>();
builder.Services.AddScoped(sp => new HttpClient { BaseAddress = new Uri(builder.HostEnvironment.BaseAddress) });
به این ترتیب این سرویس در کامپوننت RelatedProducts قابل دسترسی میشود و جایگزین سرویس HttpClient تزریقی قبلی خواهد شد. به همین جهت به فایل کامپوننت ProductStore مراجعه کرده و فقط 2 سطر آنرا تغییر میدهیم:
الف) معرفی سرویس IProductStore بجای HttpClient قبلی
@inject IProductStore ProductStore
ب) استفاده از متد GetRelatedProducts این سرویس:
private async Task LoadRelatedProducts()
{
_loadRelatedProducts = true;
_relatedProducts = await ProductStore.GetRelatedProducts(ProductId);
}
مابقی قسمتهای این کامپوننت یکی است و تفاوتی با قبل ندارد.
اکنون اگر برنامه را اجرا کنیم، پس از مشاهدهی جزئیات یک محصول، بارگذاری کامپوننت Blazor WASM آن در developer tools مرورگر کاملا مشخص است:
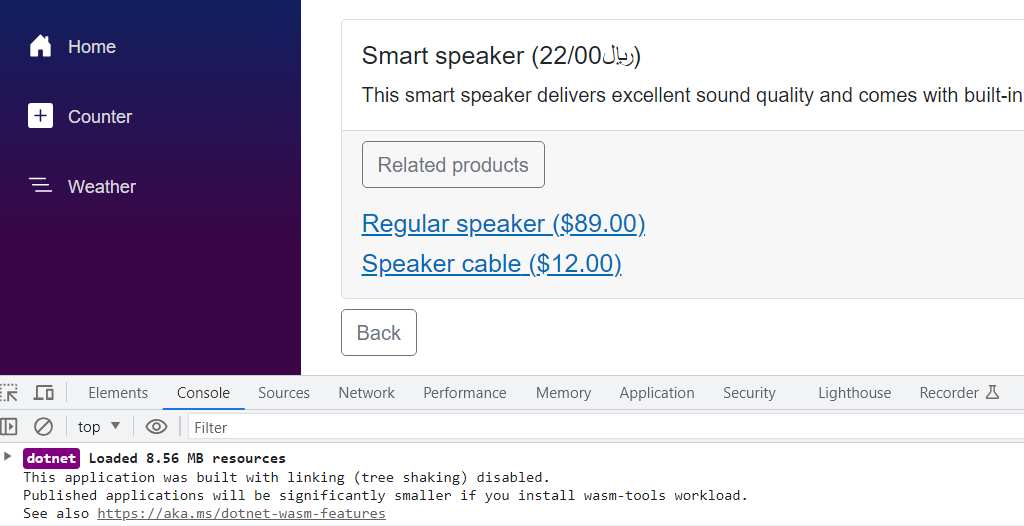
راهحل سوم: استفاده از سرویس PersistentComponentState
با استفاده از سرویس PersistentComponentState میتوان اطلاعات دریافتی از بانکاطلاعاتی را در حین pre-rendering در سمت سرور، به جزایر تعاملی انتقال داد و این روشی است که مایکروسافت برای پیاده سازی مباحث اعتبارسنجی و احراز هویت در Blazor 8x در پیشگرفتهاست. این راهحل را در قسمت بعد بررسی میکنیم.
کدهای کامل این مثال را از اینجا میتوانید دریافت کنید: Blazor8x-WebAssembly-Normal.zip 

















