در این مطلب و همینطور مطلب بعدی قرار است به مبحث لاگ فایلها Logfile بپردازیم. همانطور که میدانید سیستم IIS مثل هر سیستم دیگری لاگ هایی دارد که به مرور زمان این لاگها میتوانند مقدار زیادی از ظرفیت دیسک سخت را به خود اختصاص بدهند و این عمل میتواند موجب بروز مشکلاتی در سرور شود. به خوبی به یاد دارم که برای یکی از مشتریانم VPS تهیه نموده بودیم و بعد از یک سال با من تماس گرفت که سایت بالا نمیآید و وقتی بررسی شد، دیدم که از فضای دیسک سخت چند گیگابایتی، تنها چند مگابایت به طور ناچیز فضا برایش باقی مانده است و باعث شده است سرور از کار بیفتد. پس از بررسی متوجه شدیم تمام این فضاها توسط لاگ فایلها پر شده است و از آنجا که سرویس دهنده تا مبلغی را به عنوان مدیریت سرور، ماهانه دریافت نکند، مدیریت این سرور مجازی را به عهده نداشته اند که البته بعدها با انتقال به یک سرور دیگر از یک سرویس دهنده دیگر مشکلات ما در مورد سرور برای همیشه حل شد.
پس این داستان به خوبی روشن میکند که مدیریت این لاگها چقدر میتواند مهم و حیاتی باشد. آقای تیم وَن از تیم تحریریه مایکروسافت در بخش IIS موارد زیر را برای مدیریت لاگها بر میشمارد:
مسیر ذخیره لاگ فایلها در آدرس زیر میباشد. به این آدرس رفته و Properties دایرکتوری مورد نظر را باز کنید و در برگهی General آن، گزینهی Advanced را زده تا در کادر جدیدی که باز میشود، گزینهی Compress contents to save disk space را انتخاب کنید تا محتویات در هنگام ذخیره روی دیسک سخت فشرده شوند.
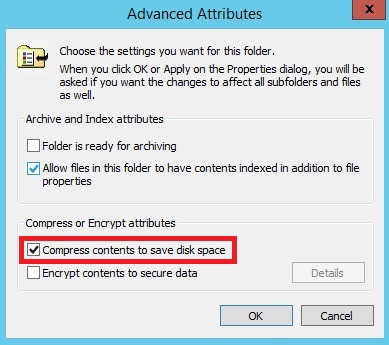
این روش سادهترین روش موجود برای مدیریت لاگ هاست ولی روش نهایی نیست و باز به مرور زمان این روش هم کارایی خودش را از دست خواهد داد. این روش بیشتر شبیه خرید زمان میباشد تا اینکه یک راه حل نهایی برای حل مشکل باشد. البته این را هم باید مدنظر داشت که موقع تیک زدن گزینه بالا عملیات فشرده سازی باعث کند شدن سرعت کامپیوتر در حین آغاز عمل ذخیره سازی لاگ فایلها هم خواهد شد. پس اگر قصد چنین کاری ذا دارید در ساعاتی که سرور کمترین فشار از طرف کاربران را دارد یا اصطلاحا پیک کاری آن پایین است انجامش دهید.
انتقال لاگ فایلها به یک سیستم راه دور
همانطور که در بالا اشاره کردیم محل پیش فرض ذخیره سازی لاگها درمسیر
%SystemDrive%\inetpub\logs\LogFiles
قرار دارد و این محل ذخیره سازی برای هر سرور یا حتی یک وب سایت خاص در صفحه تنظیمات Logging مشخص شده است و شما در میتوانید این لاگها را حتی برای کل سرور یا مربوط به یک سایت خاص، به سروری دیگر انتقال دهید. این امکان میتواند به امنیت سیستم هم کمک فراوانی کند تا اگر دیسک محلی Local Disk هم دچار مشکل شد، باز خواندن لاگ فایلها میسر باشد و با استفاده از ابزارهای تحلیل لاگ فایل ها، آنها را مورد بررسی قرار دهیم. برای تغییر محل ذخیره سازی لاگها به یک سیستم راه دور، راه حل زیر را طی کنید.
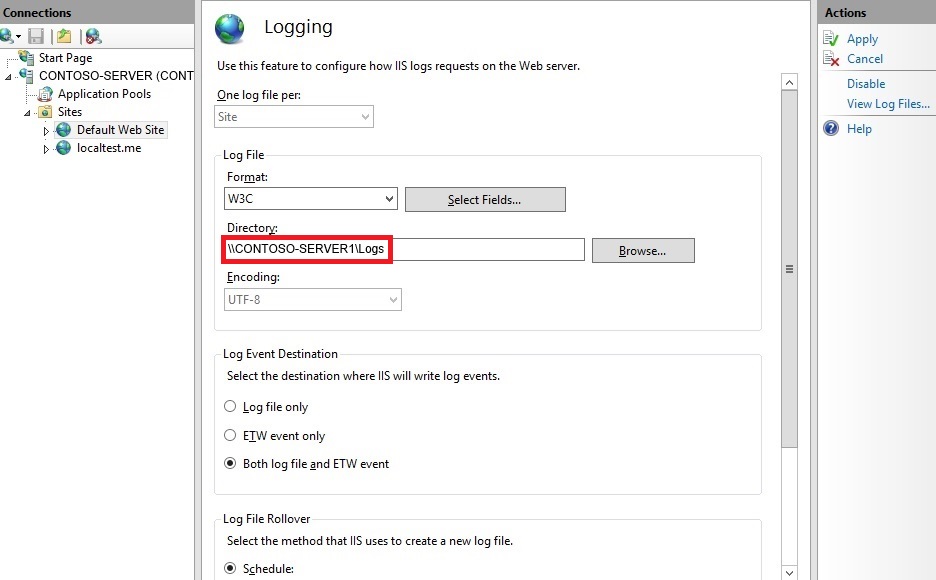
در IIS وب سایتی را که میخواهید لاگ آن انتقال یابد، انتخاب کنید؛ یا اگر لاگ کل سیستم IIS را میخواهید انتقال بدهید نام سرور را در لیست درختی انتخاب کنید و از ماژولهای سمت راست، ماژول Logging را انتخاب کنید و در قسمت Directory که محل ذخیره سازی فعلی لاگها را نوشته شده است، به صورت UNC آدرس دهی کنید. در آدرس زیر اولی نام سرور است Contoso-server1\\ و دومی هم Logs نام پوشهای که به اشتراک گذاشته شده است.
حذف لاگ فایلهای قدیمی با استفاده از اسکریپت
با این روش میتوانید لاگ فایل هایی را که بعد از مدتی معین که دلخواه شما هست، از سیستم حذف نمایید و اگر این اسکریپت را زمان بندی خودکار نمایید، میتوانید از مراقبت مداوم و ثابت این کار نیز رها شوید.
با ستفاده از VBScript بررسی میکنیم که اگر مثلا عمر لاگ فایل به 30 روز رسیده است، باید حذف شوند. خط دوم کد زیر نهایت عمر یک لاگ فایل را مشخص میکند:
sLogFolder = "c:\inetpub\logs\LogFiles"
iMaxAge = 30 'in days
Set objFSO = CreateObject("Scripting.FileSystemObject")
set colFolder = objFSO.GetFolder(sLogFolder)
For Each colSubfolder in colFolder.SubFolders
Set objFolder = objFSO.GetFolder(colSubfolder.Path)
Set colFiles = objFolder.Files
For Each objFile in colFiles
iFileAge = now-objFile.DateCreated
if iFileAge > (iMaxAge+1) then
objFSO.deletefile objFile, True
end if
Next
Next اسکریپت بالا تمامی subfolderها را برای همه سایتها بررسی کرده و لاگهای آنان را حذف میکند. ولی اگر دوست دارید این عملیات را تنها به یک وب سایت محدود کنید، باید مسیر را در خط اول دقیقتر مشخص کنید.
برای اجرای دستی اسکریپت در cmd تایپ کنید:
cscript.exe c:\scripts\retentionscript.vbs
ولی اگر میخواهید این اسکریپت در هر دورهی زمانی خاص اجرا شود، یا زمان بندی Scheduling گردد، دیگر مجبور نیستید هر بار به فکر نگهداری از لاگها باشید.
زمان بندی اجرای اسکریپت
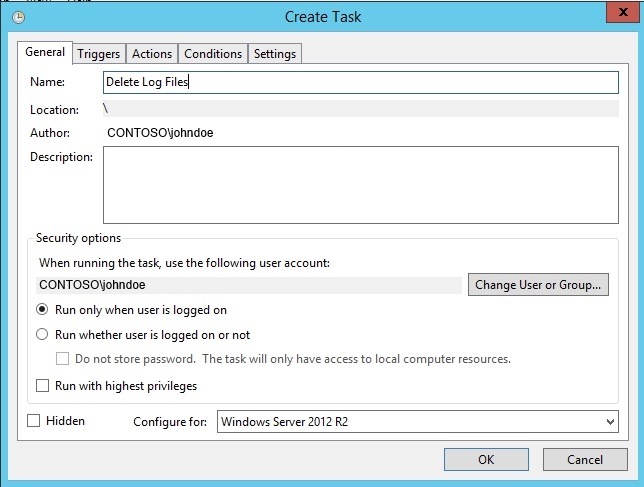
server manager (قابل تست در ویندوزهای سرور) را باز کرده و از منوی Tools گزینه Task Scheduler را انتخاب کنید و در قسمت Actions گزینه Create Task را انتخاب نمایید. در کادر باز شده نام "Delete Log Files " را برای مثال برگزینید و در قسمت Security هم کاربری که اجازه اجرای اسکریپت را دارد مشخص کنید.
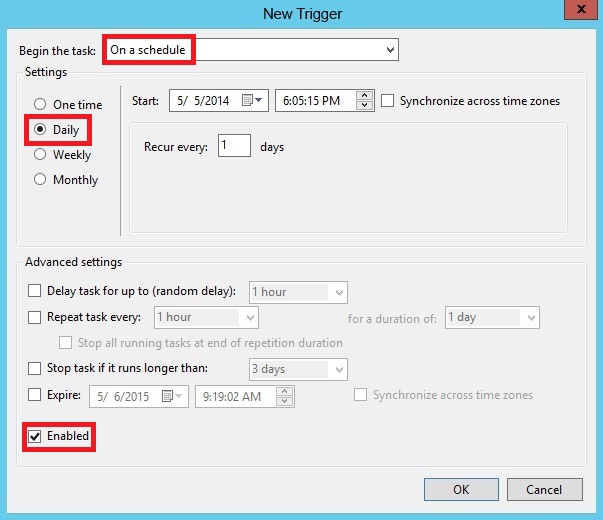
برگه Triggers را انتخاب کرده و گزینه New را انتخاب کنید و عملیات زمان بندی را تنظیم کنید و حتما بعد از زمان بندی مطمئن باشید که تیک Enabled فعال است.
در برگه Actions هم گزینه New را انتخاب کنید؛ در کادر باز شده از لیست Start a program را انتخاب کرده و در قسمت Program\script، دستور cscript را ذکر نمایید و به عنوان آرگومان ورودی Add arguments هم مسیر اسکریپت خود را ذکر نمایید و کادر را تایید کنید.
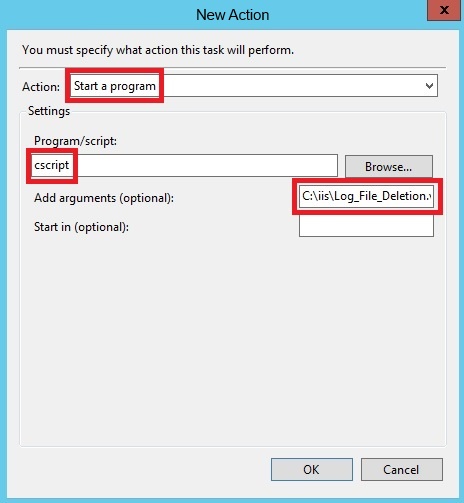
برای آغاز زمان بندی در لیست وظیفههای فعال active task pane، وظیفه ای که الان ساخته اید را اجرا کرده و به مسیر ذخیره لاگها رفته و میبینید که لاگهای مورد نظر حذف شدهاند؛ پس از صحت اجرای اسکریپت مطمئن میشویم. دوباره به لیست وظایف رفته و گزینه End را بزنید تا وظیفه، در حالت Ready قرار گیرد تا از همین الان فرایند زمان بندی اجرای اسکریپت آغاز شود.
حذف لاگ فایلها با استفاده از IIS Log Cleaner Tools
سادهترین ابزار برای مدیریت حذف لاگ فایل هاست که هر یک ساعت یکبار اجرا شده و لاگ فایلهای تاریخ گذشته را که زمانش را شما تعیین میکنید، به سمت سطل زباله که البته درستش بازیافت است Recycle Bin انتقال میدهد تا از ضرر از دست دادن لاگها جلوگیری کند که بعدا شما میتوانید آنها را به صورت دستی حذف کنید. همچنین عملیات خودکار حذف را نیز میتوان متوقف نمود.
ابتدا برنامه را از اینجا دانلود کنید. موقعیکه برنامه را اجرا کنید، در نوتیفیکیشن taskbar مینشیند و برنامه با یک پیغام به شما اعلام میکند، این اولین بار است که برنامه را باز کردهاید. پس یک سر به setting آن بزنید؛ با انتخاب گزینهی settings برنامه بسته شده و فایل Settings.txt برای شما باز میشود که مدت زمان عمر لاگ فایل و مسیر ذخیره آنها، از شما پرسیده میشود که مقدار عمر هر لاگ فایل به طور پیش فرض 30 روز و مسیر ذخیرهی لاگها همان مسیر پیش فرض IIS است که اگر شما دستی آن را تغییر داده اید، با پرسیدن آن، از محل لاگها اطمینان کسب میکند. در صورتی که قصد تغییری را در فایل، دارید آن را تغییر داده و ذخیره کنید و برنامه را مجددا اجرا کنید.

نکات نهایی در مورد این برنامه :
- اگر از ابزار IIS Cleaner Tool استفاده میکنید باید دستی سطل بازیافت را هم پاک کنید و هم اینکه میتوانید یک محدودیت حجمی برای Recycle Bin قرار دهید که اگر به یک حدی رسید، خودکار پاک کند تا مشکلی برای سیستم عامل ایجاد نشود که البته به طور پیش فرض چنین است.
- برنامه بالا به طور پیش فرض ریشهی لاگها را حذف میکند. پس اگر میخواهید فقط سایت خاصی را مد نظر داشته باشد، آدرس دایرکتوری آن را اضافه کنید. البته چون این برنامه فقط روی یک دایرکتوری کار میکند و شما چند وب سایت دارید و مثلا میخواهید سه تای آنها را پاکسازی کنید، چارهی جز استفاده از اسکریپتهای با زمان بندی ندارید.
- برنامهی بالا فقط فایل هایی با پسوند log را به سطل بازیافت انتقال میدهد.
- برنامهی بالا یک سرویس نیست و باید به طور دستی توسط کاربر اجرا گردد. پس اگر ریست هم شد باید دستی اجرا شود یا آن را به داخل پوشه startup بکشید.
- برنامه برای اجرایش نیاز به لاگین کاربر و مجوز نوشتن در آن پوشه را دارد تا به درستی کار کند.
در قسمت بعدی مبحث لاگها را ادامه خواهیم داد و با ماژول Logging در IIS و تنظیماتش آشنا خواهیم شد.








